
与之前的许多蓝筹 NFT 系列一样,蓝精灵协会传奇系列由具有不同特征和稀有程度的 PFP 组成。这些 PFP 的价值在于它们所具有的特征的组合。NFT 的稀有度等级越高,与那些具有更常见特征的 NFT 相比,其价值就越大。
对于许多这样的收藏品来说,买家在不知道它们会有哪些特征的情况下盲目铸造或购买他们的 PFP,直到它们后续“开盒”。由于稀有性会显着影响二级市场的价格,因此确保公平透明的分配至关重要(即确保稀有的 NFT 不能故意分配给某些买家)。本文从技术角度概述了我们如何设计我们的“开盒”系统来做到这一点。
简介
在讨论“开盒”策略本身之前,让我们看看我们讨论的(和实施的)不同“开盒”流程选项及其可能的影响:
方案 1:在“开盒”过程中生成通证的 ID,并将其与内部分配的 ID 联系起来。
方案 2:保持 ID 相同,以减少销毁和铸造新的 PF P的成本,并保存链上的开盒状态。
方案 3:与方案 2 相同,但将开盒状态保存在链下。
我们可以在下表中总结三种方案的优缺点:

为了避免产生交易费用,我们选择了完全链下的解决方案。现在,由于链下操纵很容易实现,我们需要定义一种创新的方式来在开盒开始之前展示公平性。为实现这一目标,我们决定采用 Bored Ape Yacht Club 使用的起源哈希解决方案,并进行一些小改动。
在以下部分中,我们将通过以下方式涵盖完成公平性和透明度所需的关键议题:
定义无操纵证明(起源哈希)
定义所使用的洗牌过程
将洗牌结果中的 ID 与预先存在的 ID 进行映射
什么是起源哈希?
在深入了解细节之前,让我们先了解一下起源哈希是什么。让我们考虑一个包含 3 个图像的集合,每个图像具有以下哈希(通过应用输出值长度都相同的比特的函数分配给一段数据的数字或字母数字字符串。哈希只是单向的将数据转换为极难逆向且可视为唯一指纹的字符串):
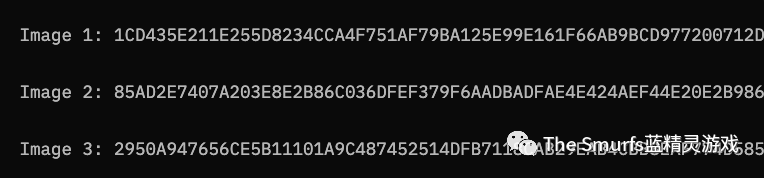
起源哈希将是以下字符链的哈希:
1CD435E211E255D8234CCA4F751AF79BA125E99E161F66AB9BCD977200712D5D85AD2E7407A203E8E2B86C036DFEF379F6AADBADFAE4E424AEF44E20E2B9864E2950A947656CE5B11101A9C487452514DFB7118CAB29EAB4CBB8EAF774D585DD
这将导致以下哈希:
echo "1CD435E211E255D8234CCA4F751AF79BA125E99E161F66AB9BCD977200712D5D85AD2E7407A203E8E2B86C036DFEF379F6AADBADFAE4E424AEF44E20E2B9864E2950A947656CE5B11101A9C487452514DFB7118CAB29EAB4CBB8EAF774D585DD" | sha3sum -a 256
因为起源哈希值是以非常具体的顺序连接的哈希,图像顺序的任何变化都会导致不同的哈希:
echo "2950A947656CE5B11101A9C487452514DFB7118CAB29EAB4CBB8EAF774D585DD85AD2E7407A203E8E2B86C036DFEF379F6AADBADFAE4E424AEF44E20E2B9864E1CD435E211E255D8234CCA4F751AF79BA125E99E161F66AB9BCD977200712D5D" | sha3sum -a 256
24d748002b8a85e0cba8a82b5490a676d35970907863dcbd771aefdc7b8e4b34
因为任何顺序的改变都会产生不同的起源哈希,所以公开这个哈希可以让大家充分相信,在发布后的图像上不会有任何操纵行为。
洗牌算法
就其本身而言,起源哈希表明不可能进行任何操纵,但这并不意味着它是公平的。我们团队可以为自己分配最稀有的 PFP,并且仍然可以获得有效的起源哈希。为了公平起见,我们需要在分配过程中添加完全随机性,以正确地将图像分配给后来用于出处哈希计算的给定 ID 或序列号。而且这个过程必须是外部可验证的:仅仅说我们做到了是不够的,我们需要展示我们是如何做到的以及我们为此使用了哪些数据。
那么什么是洗牌数据的确定性方法呢?这是 Scala(我们首选的编程语言之一)中的一小段代码,演示了它是如何工作的:
val random = new util.Random(41L)
random.shuffle(1 to 50)
我们总会得到同样的结果:一个未经排序的 ID 向量:
(24, 23, 38, 16, 36, 9, 33, 21, 37, 31, 6, 10, 17, 14, 44, 7, 48, 43, 4, 50, 47, 34, 20, 46, 11, 3, 28, 19, 2, 22, 45, 49, 13, 12, 39, 29, 35, 41, 40, 26, 32, 5, 42, 27, 15, 30, 18, 1, 25, 8)
现在,为了使这个洗牌过程公平和透明,我们需要确保:
数据是可以从外部验证的,所以我们决定使用区块哈希
它是完全不可预测的,我们无法事先知道外部可验证的数据,以避免检查是否对我们有利
对随机性的提取只能执行一次。和之前一样,如果我可以重新提取结果,我就一直提取,直到我对结果感到满意。
我们通过以下策略实现了前面的几点,使用两个不同的区块哈希值作为种子:
第一个是在我们保存根起源哈希值时使用的(起源是从艺术品 PROD 团队所有图片中按顺序计算出来的)。该交易详情:https://etherscan.io/tx/0x506ab14f5cf8d0fb0b62bcfe5075917e2f80bce0fbec6998b312be05afafba66,产生的种子是:0xae8b799c39509cefaa6ef0719d888aeabf8ced9c53f01423d4e2a201c05efb40
第二点是在第二个交易中定义的,但依赖于第一个交易。当我们执行交易时,从未来区块中获取哈希值是在同一个交易中定义的。得到的种子是:0x1872da5c60b848377a2777cb3b8b4ff1962adb7536881ad60a4d46c32d750008
对于最后一个条件,你可以参考链上代码,了解以下功能:
- setUnshuffledProvenanceHash- recordSeedFromDefinedBlock- setProvenanceHash
代币映射
因此,现在我们有了一种方法来适当对数据进行洗牌,并证明它在之前和之后都没有改变,我们只需要将代币 ID 与连续销售活动以及不同的铸造活动(水晶铸造,水桶拍卖)进行适当的映射。在我们的案例中,非常特殊的一点是,水晶铸造的蓝精灵是半公开的,因为它们与一个非常具体的蓝精灵角色相联系。
在第一批蓝精灵中(包含 50 个未设计出来的角色,还不能使用),我们有 10,000 个由艺术生产团队创作的 PFP 代币需要被映射:
5,000 PFPs 是已知的,具有预定的特征,这意味着持有 Papa Smurf PFP(源自水晶铸造)的人可以保证提取 Papa Smurf 图像后显示出来。
5,000 PFPs 是 100% 随机的,意味着没有任何限制。
为此,我们采取了一种方法,分为三步:
第一阶段:计算图像的参考哈希值,并将所有图像保存到云对象存储中(然后转移到IPFS)。所有的 PFP 都有一个从 1 到 10,000 的序列号,每个蓝精灵有 50 个连续的ID(例如:幸运蓝精灵的 ID 从 1 到 50,猎人蓝精灵的 ID 从 51 到 100,等等)。这里计算出的起源哈希值将被保存在链上。
第二阶段:按照水晶的半披露规定的顺序来映射文件。我们还计算了一个相关的起源哈希值,但它本身并不相关,因为这是一个过渡状态。
第三阶段:从链上生成的区块哈希进行最终洗牌。
这些阶段中的每一个都需要我们以不同的方式进行洗牌,我们将在下面的章节中描述。
第一阶段
为了更好地解释这个阶段,我们来将「黑客蓝精灵」作为例子,它的系统 ID 是#148(在游戏化阶段就已设置),这个蓝精灵的代币范围结果是:7351->7400。
这一阶段的结果是生成了起源哈希值,它被用作基于 10,000 PFPs 原始顺序的参考。这个出处哈希值被保存在链上,其参考值为 __unshuffledProvenanceHash.
当交易被添加到一个区块时,该区块的区块哈希被用作第二阶段的种子,以洗牌所有的 PFP。此外,一个区块的未来参考被保存下来,以定义第三阶段使用哪个区块哈希。
第二阶段
这个阶段是最关键的,因为我们需要用一个有效的 ID 来正确地分配 PFP,保证半公开的规定条件。为了做到这一点,我们遵循以下步骤:
如前所示,洗牌之后的数字是 1 - 50
每个蓝精灵,我们取前 25 个(来自洗牌后的序列),用它们的新 ID 保存。根据我们提供的洗牌例子,每个蓝精灵 PFP 的 #24 被移到了 #1的位置。再回到黑客蓝精灵的例子,他的新范围现在是 3676 到 3700,PFP 3676 与该蓝精灵的第 24 号图像是相关的。
然后把所有剩下的旧 ID 的蓝精灵,用同样的种子再次洗牌。这是为了确保蓝精灵特征不会在未显示的范围内连续出现。
这一阶段的成果是一个新的起源哈希值,但更重要的是,完成与我们在链上的内容完全一致的映射。
第三阶段
这一阶段与前一阶段非常相似,不同的是,我们只对前一阶段分配的小组进行洗牌:
洗牌之后的数字是 1 - 25
对于每个蓝精灵,我们根据新的位置重新分配代币
非水晶映射的 PFP,我们再次对它们进行洗牌
这个阶段的结果是最终的起源哈希值,它被保存在链上证明__provenanceHash 里。
当我们完成这项工作时,我们意识到第三阶段是多余的,我们可能只用第一阶段和第二阶段就能完成同样的结果。第三阶段的主要原因是为了保证 5001 到 10000 范围内的非连续代币,并确保良好的分布。
总结
当我们生成所有这些数据时,我们将使其可供消费,我们会将部分代码开源,以解释该过程的关键步骤。结果大致如下表格:
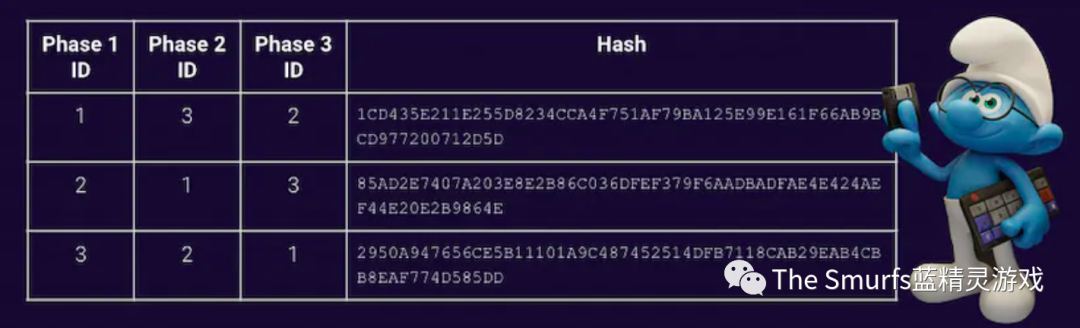
我们的目标是提供完全的透明度,让我们的社区相信我们的分配是公平的。我们和你一样兴奋,我们希望以真正的 Web3 方式来完成蓝精灵的开盒!所有步骤都在链上,公开透明!




发表评论 取消回复